
Ever wondered why your smartphone can recognise your face instantly, or how Google Maps predicts the fastest route before you even hit the road? Or maybe you’ve noticed how Spotify somehow creates playlists that match your mood perfectly. Behind all these everyday conveniences lies one powerful force: machine learning.
At its core, machine learning is all about helping computers learn from examples rather than following strict, step-by-step instructions written by a programmer. Instead of telling the computer, “If you see X, then do Y,” we feed it thousands—or even millions—of examples and let it uncover patterns on its own. It’s very similar to the way humans learn through experience. You don’t hand a child an encyclopedia and expect them to memorise every object in the world. You show them examples: “This is a dog,” “this is also a dog.” Eventually, they can recognise a dog they’ve never seen before.
Machine learning works the same way, but instead of pictures, voices, or text, it processes whatever data you give it—emails, browsing behaviour, medical scans, financial records—and gradually learns to make predictions or decisions from those patterns. The more data it sees, the better it becomes.
What Is Machine Learning, Really?

At its core, machine learning represents a complete shift from how we traditionally get computers to perform tasks. The old way involved a developer writing very specific, step-by-step instructions. For a spam filter, you might write code that says, “If an email subject contains the phrase ‘free money’, then move it to the spam folder.”
This approach is fragile and breaks easily. What happens when a clever spammer starts using “F.ree M.oney” instead? You’d have to go back and manually update your code, trapping yourself in an endless cat-and-mouse game.
Machine learning turns this entire process on its head.
Instead of feeding the computer a set of rules, you feed it a mountain of data. The machine learning model then works out the underlying rules for itself, spotting subtle connections and patterns that a human programmer might never even think to code.
This ability to learn from experience is what gives machine learning its power. It’s the engine behind your satnav finding the fastest route by analysing live traffic, or your bank instantly spotting a transaction that doesn’t fit your usual spending habits.
A Practical Example: The Spam Filter in Action
Let’s revisit that spam filter to see how this works in a step-by-step way. A machine learning model doesn’t just look for a fixed list of “bad” words. Instead, it’s trained on a huge dataset of emails that humans have already labelled as either “spam” or “not spam.”
By sifting through thousands of these examples, the model starts to build its own understanding of what spam looks like. It might discover that:
- Emails packed with capital letters and exclamation marks are often junk.
- Messages that mention large sums of money are highly suspicious.
- Emails from unknown senders that use generic greetings (“Dear Friend”) are more likely to be spam.
The model doesn’t treat these as hard rules. Instead, it weighs all these factors—and hundreds more—to calculate a probability score for each new email. If that score crosses a certain threshold, zap—it gets sent to your junk folder. This is the central idea of machine learning: using past data to make intelligent predictions about new, unseen information.
Best of all, this isn’t a one-and-done deal. Every time you mark a new email as spam, you’re providing fresh data. The system can retrain itself on this new information, getting smarter and adapting to the latest tricks spammers are using. This cycle of continuous improvement is what makes machine learning systems so effective over time.
Before we go deeper, it helps to get comfortable with a few fundamental concepts. Here’s a quick table to get you started.
Core Machine Learning Concepts at a Glance
| Concept | Simple Explanation | Actionable Example |
|---|---|---|
| Model | The “brain” of the system. It’s the output of the training process and is what makes predictions on new data. | The specific logic your email service uses to decide if an incoming message is spam. |
| Training | The process of “teaching” the model by feeding it labelled data so it can learn patterns. | Showing the model thousands of emails already marked as “spam” or “not spam.” |
| Prediction | When the trained model makes a guess or decision about new, unseen data. | The model analyzing a new email and assigning it a “spam score” of 98%. |
| Features | The individual data points or characteristics the model uses to make a prediction. | For an email, features could be the sender’s address, the subject line, or the number of capitalized words. |
Understanding these basic terms will make it much easier to grasp the different types of machine learning algorithms and how they work, which we’ll explore next.
The Three Fundamental Ways Machines Learn
Machine learning isn’t a single, monolithic thing. It’s more like a collection of different learning styles, much like how people learn. Some of us learn best by studying a textbook with clear answers, others by trial and error, and some by just finding patterns on our own. Each of these approaches is a great fit for certain problems and data types.
To really get a handle on what machine learning can do in the real world, you need to understand these three core methods: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Each one offers a unique way to train a model, depending on what you’re trying to achieve and the data you have to work with.
Supervised Learning: Teaching with an Answer Key
Supervised learning is easily the most common and direct form of machine learning. The best way to think about it is like studying for an exam with a stack of flashcards. Each card has a question on the front (the input data) and the correct answer on the back (the label). By going through thousands of these cards, you learn to connect the questions to their answers.
In machine learning terms, this means we feed an algorithm a massive dataset where every piece of data is already labelled with the right outcome. The model’s job is simply to figure out the relationship—the hidden rules—between the inputs and their corresponding labels. Once it learns this, it can accurately predict outcomes for new, unlabelled data it has never seen before.
Practical Example: Credit Card Fraud Detection
- The Data: A history of millions of past credit card transactions.
- The Labels: Every transaction is tagged as either “fraudulent” or “legitimate.”
- The Goal: The model studies this data to learn the subtle patterns of fraudulent activity, like unusual purchase locations, abnormally large transaction amounts, or a rapid series of purchases.
- Actionable Insight: Once trained, the model monitors new transactions in real-time. If a purchase triggers the patterns it has learned to associate with fraud, it immediately flags it for review, preventing a fraudulent charge before it clears.
Supervised learning shines when it comes to prediction and classification because it learns from a “ground truth.” Think of it as a highly advanced pattern-matching system trained on historical data where we already know all the answers.
This learning style is also the backbone of many modern customer service tools. To see how this tech is used locally, you can check out our guide on AI chatbots in Nigeria, which often rely on supervised models to understand and correctly respond to customer questions.
Unsupervised Learning: Finding Patterns in Chaos
Now, let’s switch gears. Imagine someone hands you a massive, jumbled box of LEGO bricks. There are no instructions, no pictures of a finished model—just a chaotic pile of pieces. What would you do? You’d probably start sorting them instinctively, grouping them by colour, shape, and size to bring some order to the mess. That, right there, is the core idea behind unsupervised learning.
With this approach, we give the machine learning model data that has no labels. There’s no “correct answer” for it to learn from. The model’s entire purpose is to dive into the data and discover hidden structures, clusters, or patterns all by itself. It’s all about discovery, not prediction.
Practical Example: Customer Segmentation
- The Data: A database filled with customer information—purchase history, browsing behaviour, demographics, and so on.
- The Labels: There are none. It’s just raw, unorganised information.
- The Goal: The model sifts through everything and groups customers into distinct segments based on their shared traits and behaviours.
- Actionable Insight: The model might uncover a group of “high-spending weekend shoppers,” another of “budget-conscious weekday browsers,” and maybe a third cluster of “new users who only buy sale items.” A business can then create highly targeted marketing campaigns for each group, such as sending a VIP offer to the high-spenders and a discount code to the budget-conscious group.
Reinforcement Learning: Learning Through Trial and Error
Reinforcement learning operates on a completely different principle. Think of it like training a dog to do a trick. You don’t give the dog flashcards or ask it to sort its toys. Instead, the dog tries an action (like sitting), and if it does the right thing, you give it a reward (a treat). If it does something else, it gets nothing. Through this simple feedback loop, the dog eventually learns which actions lead to the best rewards.
This is precisely how reinforcement learning works. An AI “agent” is placed in an environment where it learns to make decisions by performing actions and receiving feedback as rewards or penalties. The agent’s only goal is to figure out how to maximise its total reward over time.
Practical Example: Training an AI to Play a Video Game
- The Agent: The AI player itself.
- The Environment: The game world, with all its rules and challenges.
- The Actions: Moving left, right, jumping, shooting—whatever the controls allow.
- The Reward: Gaining points for beating enemies or finishing a level. It gets a penalty (loses points) for taking damage.
- Actionable Insight: At first, the agent’s actions are random. But after millions of attempts, it connects specific actions (like jumping at a certain time) with higher scores. This process allows it to develop complex strategies, sometimes far beyond what human players can do. This same method is used to optimize supply chains by rewarding models for finding more efficient routes.
Common Machine-Learning Algorithms You Should Know

Now that we’ve covered the three main ways machines learn, we can get into the specific “tools” in the machine-learning toolkit. These tools are called algorithms, and each one is built to tackle a particular kind of problem. You don’t need to be a maths genius to get started; the real key is knowing what each algorithm does and, more importantly, when to use it.
Think of it like a toolbox. You wouldn’t use a sledgehammer to hang a picture frame, and you wouldn’t use a screwdriver to chop wood. Picking the right algorithm is just as critical for getting the results you’re after.
Let’s break down some of the most common and powerful ones you’ll come across.
Comparing Popular Machine Learning Algorithms
To give you a quick overview, here’s a table that breaks down some common algorithms by what they do best and where you might see them in action.
| Algorithm | Primary Use | Problem Type | Practical Example |
|---|---|---|---|
| Linear Regression | Prediction | Regression | Forecasting product sales for next quarter based on ad spend. |
| Decision Trees | Classification | Classification | Deciding if a loan application should be ‘Approved’ or ‘Denied’. |
| Random Forests | Classification/Regression | Classification/Regression | Predicting which customers are likely to churn with high accuracy. |
| K-Means Clustering | Grouping | Clustering | Segmenting website visitors into distinct user personas for targeted ads. |
| Support Vector Machines | Classification | Classification | Identifying cancerous vs. non-cancerous cells from medical images. |
| Neural Networks | Pattern Recognition | Classification/Regression | Powering facial recognition in your phone or translating languages. |
This table is just a starting point. The real magic happens when you understand how these tools work in practice.
Linear Regression: Predicting Continuous Values
Linear Regression is often the first algorithm anyone learns in machine learning, and for good reason—it’s simple, powerful, and incredibly practical. Its main job is to find the relationship between two things to predict a continuous numerical value. Imagine drawing the best possible straight line through a scatter plot of data points; that’s the essence of Linear Regression.
Practical Example: Estimating House Prices
A real estate agency wants a better way to price homes.
- Gather Data: Collect data on hundreds of properties, including their size in square metres (input) and their final sale price (output).
- Train the Model: The algorithm crunches this data, learning the direct link between size and price. It discovers that, on average, every extra square metre adds a certain amount to the house’s value.
- Make a Prediction: Now, when a new 150-square-metre home is listed, the agency can plug in the size, and the model provides a solid price estimate based on the learned relationship.
- Actionable Insight: This gives agents a data-backed starting point for pricing, leading to more consistent and realistic valuations.
Decision Trees and Random Forests: Making Clear Choices
If Linear Regression draws a line, a Decision Tree builds a flowchart. It functions by asking a cascade of simple “if/then” questions to chop the data into smaller and smaller groups until it reaches a conclusion. It’s incredibly intuitive because it reflects how we often make decisions in real life.
A Random Forest elevates this idea. Instead of trusting just one tree, it constructs hundreds or even thousands of them and then polls them all for the most popular answer. This “wisdom of the crowd” approach makes it far more accurate and less prone to errors than a single tree.
A decision tree is fantastic for classification tasks where you need an explainable outcome. It literally shows you a map of how it arrived at its decision.
Practical Example: Screening Loan Applications
A bank uses a Decision Tree to screen loan applications. The tree might ask:
- Is the applicant’s credit score above 650?
- Is their monthly income greater than ₦200,000?
- Have they been with their current employer for more than two years?
Based on the answers, the application travels down the appropriate branches until it lands on a final “Approve” or “Deny” verdict. The actionable insight here is that the bank gets not only a decision but also a clear, auditable reason for that decision.
K-Means Clustering: Grouping Similar Items
K-Means Clustering is a classic unsupervised learning algorithm. Remember our earlier analogy of sorting a mixed box of LEGO bricks without any instructions? That’s exactly what K-Means does with data. You just tell it how many groups (the “K”) you want to find, and it automatically organises your data into distinct clusters based on their similarities.
Practical Example: Retail Customer Segmentation
An online store wants to understand its customers better to personalise its marketing.
- Gather Data: Collect customer data (purchase history, time on site, items viewed).
- Choose ‘K’: The store decides it wants to find 3 distinct groups (K=3).
- Run the Algorithm: K-Means runs and identifies these clusters:
- Cluster 1: “The Bargain Hunters” – Customers who primarily buy discounted items.
- Cluster 2: “The Loyalists” – Shoppers who repeatedly buy from a few specific brands.
- Cluster 3: “The High Rollers” – Customers who shop infrequently but make very large purchases.
- Actionable Insight: The store can now send discount codes to the Bargain Hunters and notifications about new arrivals from their favorite brands to the Loyalists, making its marketing far more effective and personalized.
These are just a few of the foundational algorithms that drive many of the smart applications we use daily. To go even deeper and understand the engines behind modern AI like ChatGPT, it’s worth exploring the mechanisms behind Transformer models, which represent the next evolution in machine learning architecture.
The Machine Learning Project Workflow: A Step-by-Step Guide
Taking a machine learning concept from a bright idea to a working application isn’t magic. It follows a clear, repeatable workflow. Think of it less like a rigid checklist and more like a strategic roadmap that keeps your project grounded and ensures the final result actually solves a real-world problem.
If you skip or rush a stage, you risk building a model that’s inaccurate, biased, or just plain useless. It’s a bit like baking a cake; every ingredient and every step matters. This step-by-step guide walks you through a typical project cycle.
Step 1: Define The Business Problem
Before you even think about data, the first and most critical step is to figure out what you’re actually trying to accomplish. What’s the point? For example, a model that predicts customer churn with 99% accuracy is worthless if the business has no plan to use that information to keep customers.
This stage is all about asking the right questions:
- What specific problem are we trying to solve? (e.g., “We need to reduce the number of customer support tickets.”)
- How will we know if we’ve succeeded? (e.g., “A 20% drop in ticket volume within three months.”)
- What kind of information might we need? (e.g., “Ticket history, customer profiles, product usage data.”)
Actionable Insight: A well-defined problem becomes the North Star for the entire project. It guides every decision, from the data you collect to the algorithms you choose, ensuring all the technical effort stays focused on tangible business goals.
Step 2: Collect and Prepare The Right Data
With a clear goal in mind, it’s time to get your hands on the data. This is where the old saying “garbage in, garbage out” really hits home. Machine learning models are completely dependent on the quality of the data they learn from. This phase involves two main jobs: gathering the data and then cleaning it up.
Data preparation is notoriously the most time-consuming part of any project, sometimes eating up as much as 80% of the total time. It’s a painstaking but essential process that includes:
- Handling Missing Values: Figuring out what to do with empty cells—should you delete the record or fill in the blank using a statistical best guess?
- Correcting Errors: Fixing simple typos or standardising inconsistent entries (like “NG” vs. “Nigeria”).
- Feature Engineering: This is a bit more creative. It involves creating new, more insightful data points from the ones you already have to help the model find stronger patterns. For instance, creating a “day of the week” feature from a timestamp.
For anyone managing these complex workflows, mastering data science project management is a vital skill for keeping everything on track.
Step 3: Select and Train The Model
Now for the fun part. With clean data at the ready, you can start picking the right algorithm for your problem. If you’re trying to predict a number (like future sales), a regression algorithm is a solid choice. If you’re sorting things into groups (like ‘spam’ or ‘not spam’), then a classification algorithm like a Decision Tree or Random Forest would be a better fit.
Training is where the model actually learns. We typically split our dataset into two piles: a training set to teach the model and a testing set that we keep hidden away to check its performance later. The model crunches through the training data, tweaking its internal settings over and over again until it finds the patterns connecting the inputs to the correct outputs.
This diagram shows a simple view of this core cycle, from raw data to a trained model ready for evaluation.
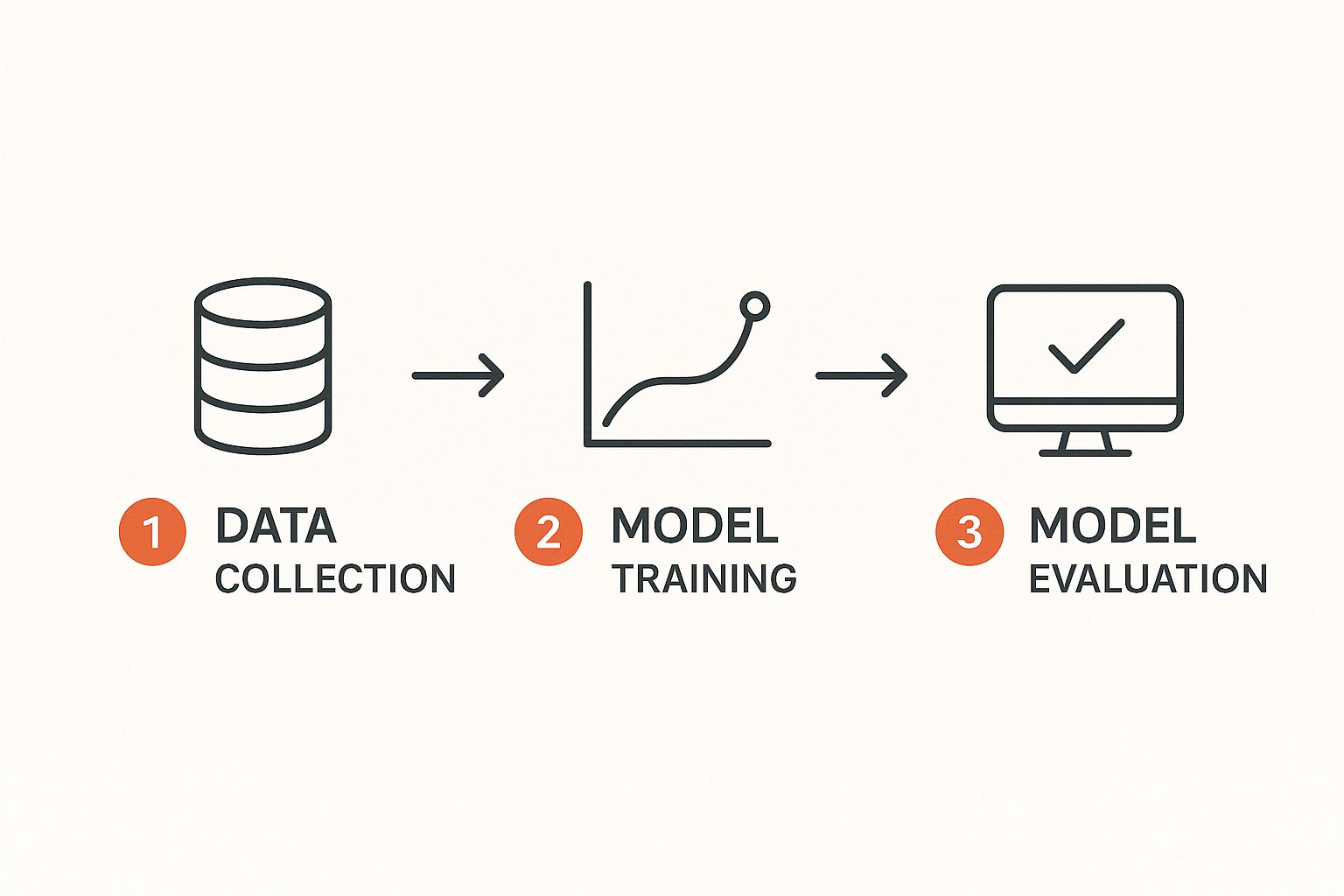
It’s a great visual that captures how we refine raw information into an intelligent system.
Step 4: Evaluate, Deploy, and Monitor
Once the model is trained, we bring out that hidden testing set. This is the moment of truth. We test our model against data it has never seen before to get an honest assessment of how it will perform in the real world. We use metrics like accuracy, precision, and recall to score its performance.
If the results aren’t good enough, it’s back to the drawing board. Maybe we need more diverse data, or perhaps a different algorithm would work better.
When you finally have a model that meets your success criteria, it’s time for deployment. This means plugging it into a live environment—like a website, app, or internal dashboard—where it can start making real predictions on fresh data. But the job isn’t done. Models can become less accurate over time as the world changes, a problem we call “model drift.” Continuous monitoring is crucial to catch this and ensure the model stays effective.
To see some of these deployed models in action, you can explore our list of free AI for content creation tools and see how they work in practice.
How Machine Learning Is Transforming Industries

This is where the rubber meets the road. We’ve talked about what machine learning is and how it works, but now it’s time to explore the real-world impact. How is it actually creating value and shaking things up in major sectors like banking, healthcare, and retail?
Make no mistake, machine learning isn’t just a buzzword anymore; it’s a practical tool driving tangible business results. Companies are using it to spot fraud with pinpoint accuracy, help diagnose diseases earlier, and deliver personalised shopping experiences that feel almost psychic.
Let’s dive into a few powerful examples of machine learning in action.
Finance and Fraud Detection
The financial world was one of the first to truly embrace machine learning, and for a very good reason: security. Old-school fraud detection systems were clumsy. They relied on rigid, simple rules, like flagging any transaction made in a foreign country. This approach was slow and created a ton of false alarms, which meant frustrating customers by blocking their perfectly legitimate purchases.
Machine learning models, on the other hand, learn the unique “heartbeat” of each customer’s spending habits. They can process dozens of signals in the blink of an eye, asking questions like:
- Transaction Amount: Is this purchase way bigger than their usual spending?
- Location: Is the card being used in a city the customer has never visited before?
- Time of Day: Does this person normally shop at 3 AM?
- Purchase Frequency: Are multiple transactions happening one after another, very quickly?
By weighing all these factors together, the model calculates a fraud risk score for every single transaction in milliseconds. Actionable Insight: If a purchase strays too far from the customer’s known behavior, it gets flagged for review or blocked instantly. This dynamic, self-improving system has slashed fraud rates while causing fewer headaches for genuine customers.
Healthcare and Medical Diagnostics
In healthcare, machine learning is becoming an invaluable partner for doctors, helping them make sense of complex medical data faster and more accurately. One of its most profound impacts is in analysing medical images.
Radiologists spend years training their eyes to spot the faintest signs of diseases like cancer in X-rays, CT scans, and MRIs. But machine learning models, especially deep learning networks, can be trained on enormous datasets containing millions of medical scans. In doing so, they learn to identify incredibly subtle patterns and anomalies—some of which might even be invisible to the human eye.
Actionable Insight: A machine learning model doesn’t get tired or distracted. It can screen thousands of images with unwavering consistency, serving as a reliable “second pair of eyes” to help clinicians prioritize urgent cases and catch diseases at their earliest, most treatable stages.
For a deeper look into how machine learning is making a difference in a specific field, check out these insights on Machine Learning for Education.
Retail and Personalisation
Have you ever browsed an online store and felt like it was designed just for you? That’s the magic of machine learning. Retailers are using it to create hyper-personalised shopping experiences that go far beyond old-fashioned, one-size-fits-all marketing.
Recommendation engines are the classic example. By analysing your browsing history, previous purchases, and even items you’ve added to your cart but haven’t bought, these algorithms make educated guesses about what you might want next. It’s why Amazon suggests products you actually find useful, and how Spotify crafts a “Discover Weekly” playlist that introduces you to your new favourite artist.
Actionable Insight: This personalisation allows businesses to showcase the most relevant products to each individual customer, significantly increasing the likelihood of a sale and fostering greater customer loyalty. It transforms marketing from a broadcast to a conversation. This even extends to creating the marketing materials themselves, as seen in AI for content creation.
The economic ripple effect of this shift is staggering. One report estimates AI could add nearly $1 trillion to Southeast Asia’s GDP by 2030. This surge is being led by countries like Singapore, where 46% of businesses have already adopted AI tools, and Malaysia, which has attracted over $22 billion in investments to build out its AI infrastructure. You can find more details about how AI is powering this growth.
Ready to Start Your Machine Learning Journey? Here’s How
Let’s be clear: the best way to learn is by doing. Theory is essential, of course, but nothing makes concepts stick quite like hands-on practice. By tackling projects from the very beginning, you’ll not only solidify your understanding but also start building a portfolio that shows people what you’re capable of.
An Actionable Four-Step Path for Beginners
Diving into a new field can feel like trying to drink from a firehose. That’s why a structured path is so important. This approach breaks the learning process into smaller, more manageable pieces, making sure you have a solid foundation before you start climbing higher. Think of it as your guided tour of the machine learning world.
Here’s a simple, four-step guide to get you moving:
-
Start with the Fundamentals (Online Courses): Begin your journey on reputable platforms like Coursera or edX. Find a good introductory course that walks you through the core ideas—supervised, unsupervised, and reinforcement learning. These courses provide the essential scaffolding you need.
-
Get Comfortable with the Tools: Every craft has its tools. In machine learning, you’ll want to get familiar with a couple of key Python libraries:
- Scikit-learn: This is the perfect starting point. It offers straightforward, efficient tools for data analysis and implementing classic algorithms.
- TensorFlow or PyTorch: Once you’ve got the basics down, pick one of these more advanced libraries for deep learning. Don’t try to learn both at once!
-
Practise on Real-World Datasets: Theory is one thing, but making it work with messy, real-world data is another. Websites like Kaggle are fantastic resources, offering free datasets for everything from predicting house prices to classifying images. Joining a beginner-friendly competition is a brilliant way to test your skills on actual problems.
-
Build Your First Project: Now it’s time to fly solo. Choose a simple but complete project, like a model that predicts movie ratings or a spam filter for text messages. The goal here is to experience the entire workflow on your own, from cleaning the data all the way to evaluating your final model.
Actionable Insight: The real learning begins the moment you step away from tutorials and start solving problems on your own. Building a project—no matter how small—forces you to face and fix real challenges. That’s where genuine skill is forged.
This project-first mindset is a lot like how great marketing works, where practical campaigns deliver the best results. If you’re looking to grow in other digital areas, our guide on digital marketing for beginners follows a similar, action-focused philosophy. By concentrating on building and experimenting, you’ll quickly find that abstract ideas become tangible skills, and you’ll be well on your way.
Your Machine Learning Questions, Answered
As you start to get your head around machine learning, a few questions always seem to come up. Let’s tackle some of the most common ones to help piece everything together.
What’s the Difference Between AI, Machine Learning, and Deep Learning?
It helps to think of them as Russian nesting dolls.
The biggest doll is Artificial Intelligence (AI). This is the broad, big-picture idea of building machines that can mimic human intelligence in some way, whether that’s thinking, acting, or reasoning.
- Practical Example: AI is the concept behind a smart assistant like Siri or a self-driving car.
Inside AI, you’ll find Machine Learning (ML). This is a specific, and currently the most successful, way to achieve AI. Instead of being programmed with rigid, step-by-step instructions, ML systems are designed to learn patterns and make decisions directly from data.
- Practical Example: ML is the engine that allows Netflix to learn your viewing habits and recommend movies.
Finally, the smallest doll is Deep Learning. This is a very specialised subfield of machine learning. It uses complex, multi-layered structures called neural networks to tackle highly intricate problems, like recognising objects in photos or understanding human speech.
- Practical Example: Deep learning powers the facial recognition that unlocks your phone.
Do I Need to Be a Maths Whizz to Learn Machine Learning?
Absolutely not, especially when you’re just starting out. While a solid grasp of linear algebra, calculus, and statistics is essential if you want to invent new algorithms or work in academic research, it’s not a barrier to entry for applying ML to solve real-world problems.
Modern tools and libraries, like Scikit-learn, do all the heavy mathematical lifting for you. This frees you up to concentrate on the practical side of things—understanding the problem you’re trying to solve and figuring out why a particular model works.
Actionable Insight: For beginners, a strong conceptual understanding of what the algorithms do is far more valuable than memorising the formulae behind them. Focus on building practical projects first. You can always dive deeper into the maths as you advance and your projects demand it.
What Are the Biggest Hurdles in Machine Learning?
For all its power, machine learning isn’t a magic wand. The field is grappling with some serious challenges—not just technical puzzles, but also practical and ethical ones that everyone in the space has to navigate.
Some of the most common roadblocks include:
- Data Quality and Bias: Your model is only ever as good as its data. Finding clean, high-quality, and unbiased data is often the hardest part of any project. If your training data for a hiring tool is historically biased against a certain demographic, your model will be too, leading to unfair outcomes.
- Explainability (The “Black Box” Problem): With complex models like deep neural networks, it can be incredibly difficult to pinpoint why it made a certain prediction. This is a major issue in fields like finance, where regulators require clear explanations for decisions like denying a loan.
- Computational Cost: Training large models, particularly in deep learning, demands a huge amount of processing power. This can be very expensive and consume a lot of energy.
- Ethical Considerations: Making sure data is kept private, using AI responsibly, and preventing its misuse are massive concerns. The entire industry is actively working on standards and solutions.
Ready to go from learning to creating? With RichlyAI, you can use AI to generate high-quality text, images, and code with ease. Sign up for a free plan and start building with powerful tools today.